K-MEANS LÀ GÌ
1. Giới thiệu
Trong bài trước, chúng ta vẫn làm quen cùng với thuật tân oán Linear Regression - là thuật tân oán dễ dàng và đơn giản độc nhất vô nhị trong Supervised learning. Bài này tôi đã trình làng một trong những thuật toán thù cơ bản duy nhất trong Unsupervised learning - thuật tân oán K-means clustering (phân các K-means).
Bạn đang xem: K-means là gì
Trong thuật tân oán K-means clustering, chúng ta phân vân nhãn (label) của từng điểm dữ liệu. Mục đích là làm cho thể nào nhằm phân dữ liệu thành các các (cluster) không giống nhau thế nào cho dữ liệu trong cùng một nhiều gồm đặc thù như là nhau.
Ví dụ: Một công ty hy vọng tạo ra rất nhiều cơ chế chiết khấu cho phần đa đội người sử dụng khác nhau dựa vào sự xúc tiến thân mỗi khách hàng cùng với chủ thể kia (thời gian là khách hàng hàng; số tiền quý khách vẫn chi trả đến công ty; độ tuổi; giới tính; thành phố; nghề nghiệp; …). Giả sử chủ thể đó có nhiều dữ liệu của đa số người tiêu dùng mà lại chưa tồn tại giải pháp như thế nào phân chia cục bộ người sử dụng kia thành một trong những nhóm/cụm khác biệt. Nếu một fan biết Machine Learning được đặt thắc mắc này, phương pháp trước tiên anh (chị) ta nghĩ về đến đang là K-means Clustering. Vì nó là một trong giữa những thuật toán thù trước tiên nhưng anh ấy tìm kiếm được trong số cuốn sách, khóa học về Machine Learning. Và tôi cũng chắc hẳn rằng anh ấy sẽ phát âm blog Machine Learning cơ phiên bản. Sau Lúc sẽ phân ra được từng team, nhân viên đơn vị đó rất có thể lựa chọn ra một vài quý khách trong mỗi nhóm nhằm ra quyết định xem mỗi team khớp ứng cùng với đội quý khách hàng như thế nào. Phần Việc ở đầu cuối này bắt buộc sự can thiệp của nhỏ tín đồ, tuy nhiên lượng quá trình đã có rút ít gọn gàng đi rất nhiều.
Ý tưởng đơn giản dễ dàng nhất về cluster (cụm) là tập thích hợp các điểm sinh hoạt gần nhau vào một không gian nào đó (không khí này hoàn toàn có thể có khá nhiều chiều trong ngôi trường vừa lòng thông tin về một điểm dữ liệu là hết sức lớn). Hình dưới là 1 trong những ví dụ về 3 nhiều dữ liệu (trường đoản cú giờ tôi sẽ viết gọn gàng là cluster).
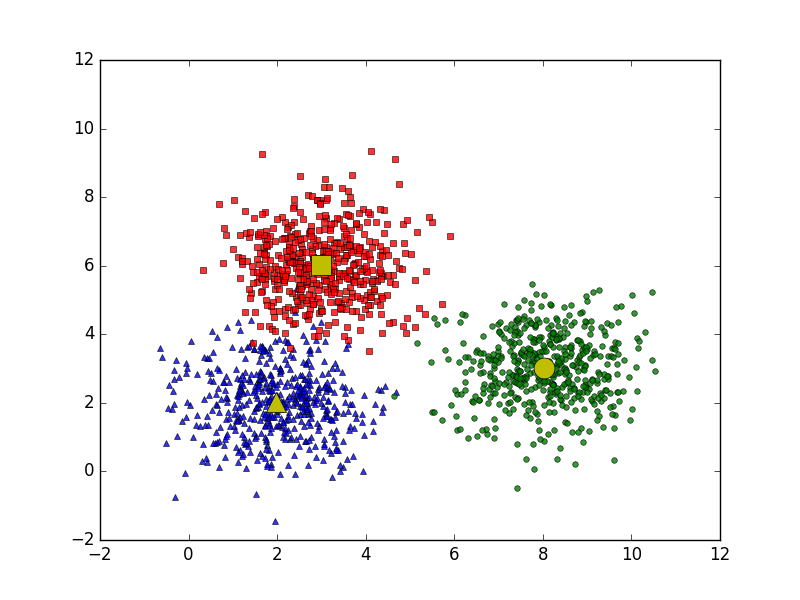
Bài toán thù với 3 clusters.
Giả sử mỗi cluster có một điểm thay mặt đại diện (center) color vàng. Và phần nhiều điểm bao quanh từng center thuộc vào cùng nhóm với center kia. Một phương pháp dễ dàng độc nhất, xét một điểm bất kỳ, ta xét coi đặc điểm này sát cùng với center như thế nào tốt nhất thì nó ở trong về thuộc nhóm cùng với center kia. Tới trên đây, chúng ta tất cả một bài xích tân oán trúc vị: Trên một vùng biển hình vuông vắn Khủng có tía hòn đảo hình vuông vắn, tam giác, cùng tròn màu quà như hình bên trên. Một điểm trên biển được call là ở trong vùng biển của một đảo giả dụ nó nằm gần đảo này hơn so với nhị đảo cơ . Hãy khẳng định ranh giới lãnh hải của các hòn đảo.
Hình bên dưới đây là một hình minh họa mang lại Việc phân loại lãnh hải giả dụ có 5 hòn đảo không giống nhau được biểu diễn bằng các hình trụ màu sắc đen:
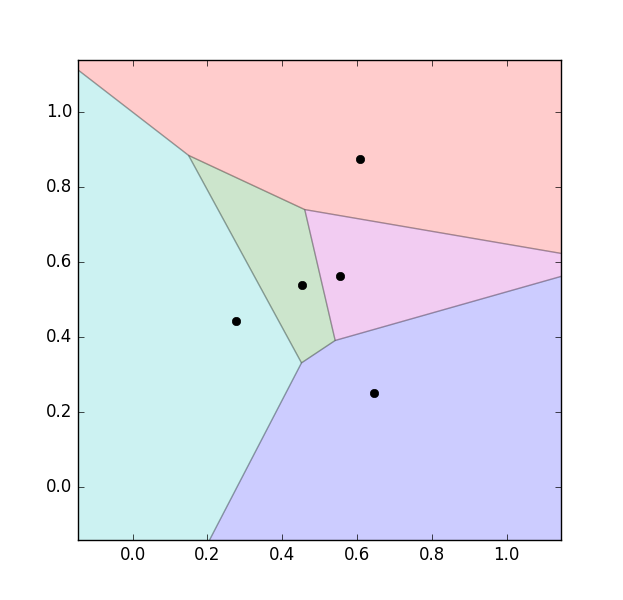
Phân vùng lãnh hải của mỗi hòn đảo. Các vùng khác nhau gồm màu sắc khác nhau.
Chúng ta thấy rằng đường phân định giữa những hải phận là các con đường thẳng (đúng chuẩn hơn thì chúng là những mặt đường trung trực của các cặp điểm sát nhau). Vì vậy, vùng biển của một hòn đảo vẫn là 1 trong hình đa giác.
Cách phân chia này vào tân oán học tập được Gọi là Voronoi Diagram.
Trong không gian cha chiều, rước ví dụ là các địa cầu, thì (tạm thời Hotline là) lãnh không của mỗi hành tinh sẽ là một trong những nhiều diện. Trong không khí nhiều chiều hơn, chúng ta sẽ có được đông đảo máy (mà lại tôi Gọi là) khôn xiết nhiều diện (hyperpolygon).
Quay lại với bài bác toán phân team và cụ thể là thuật tân oán K-means clustering, bọn họ đề xuất một chút ít so sánh toán thù học tập trước lúc đi tới phần nắm tắt thuật tân oán ở đoạn bên dưới. Nếu các bạn không thích phát âm rất nhiều về toán thù, chúng ta có thể bỏ qua mất phần này. (Tốt tuyệt nhất là đừng bỏ qua mất, bạn sẽ tiếc đấy).
2. Phân tích toán thù học
Mục đích cuối cùng của thuật tân oán phân team này là: từ bỏ tài liệu nguồn vào và con số đội họ mong tìm, hãy chỉ ra center của mỗi nhóm với phân các điểm dữ liệu vào những team tương ứng. Giả sử thêm rằng mỗi điểm tài liệu chỉ nằm trong vào đúng một đội.
Một số ký hiệu toán học
Giả sử tất cả (N) điểm dữ liệu là ( mathbfX =
Với từng điểm tài liệu ( mathbfx_i ) đặt (mathbfy_i =
Ràng buộc của (mathbfy_i ) rất có thể viết dưới dạng toán thù học tập như sau:< y_ik in �, 1,~~~ sum_k = 1^K y_ik = 1 ~~~ (1)>
Hàm mất đuối và bài toán thù tối ưu
Nếu ta coi center (mathbfm_k ) là center (hoặc representative) của từng cluster và ước lượng tất cả những điểm được phân vào cluster này bởi (mathbfm_k ), thì một điểm tài liệu (mathbfx_i ) được phân vào cluster (k) sẽ bị không đúng số là ( (mathbfx_i - mathbfm_k) ). Chúng ta ước muốn không đúng số này còn có trị tuyệt đối nhỏ tuổi tuyệt nhất yêu cầu (y như vào bài bác Linear Regression) ta đang tra cứu cách để đại lượng sau đây đạt cực hiếm bé dại nhất: <|mathbfx_i - mathbfm_k|_2^2>
ngoài ra, vày (mathbfx_i ) được phân vào cluster (k) nên (y_ik = 1, y_ij = 0, ~forall j
eq k ). Khi đó, biểu thức bên trên sẽ được viết lại là:
(Hy vọng khu vực này không thật cạnh tranh hiểu)
Sai số đến tổng thể dữ liệu vẫn là:
Trong đó ( mathbfY =
Tóm lại, họ nên buổi tối ưu bài bác tân oán sau:
< extsubject to: ~~ y_ij in �, 1~~ forall i, j;~~~ sum_j = 1^K y_ij = 1~~forall i>
(subject to tức là thỏa mãn điều kiện).
Nhắc lại tư tưởng (argmin): Chúng ta biết ký kết hiệu (min) là quý giá nhỏ tuổi độc nhất vô nhị của hàm số, (argmin) đó là cực hiếm của thay đổi số nhằm hàm số kia đạt quý hiếm bé dại nhất đó. Nếu (f(x) = x^2 -2x + 1 = (x-1)^2 ) thì quý hiếm nhỏ tuổi duy nhất của hàm số này bởi 0, dành được Lúc (x = 1). Trong ví dụ này (min_x f(x) = 0) cùng (argmin_x f(x) = 1). Thêm ví dụ không giống, nếu (x_1 = 0, x_2 = 10, x_3 = 5) thì ta nói (argmin_i x_i = 1) vì chưng (1) là chỉ số nhằm (x_i) đạt quý hiếm nhỏ tuyệt nhất (bởi (0)). Biến số viết bên dưới (min) là trở nên số cúng ta đề xuất tối ưu. Trong những bài bác toán buổi tối ưu, ta thường xuyên quan tâm tới (argmin) hơn là (min).
Thuật toán buổi tối ưu hàm mất mát
Bài toán ((2)) là 1 trong những bài bác toán cạnh tranh tìm kiếm điểm buổi tối ưu vì nó bao gồm thêm các điều kiện ràng buộc. Bài toán này nằm trong các loại mix-integer programming (ĐK trở thành là số nguyên) - là một số loại khôn cùng khó khăn search nghiệm buổi tối ưu cục bộ (global optimal point, tức nghiệm tạo cho hàm mất đuối đạt quý hiếm nhỏ tốt nhất gồm thể).
Xem thêm: Thiếu Máu Cần Phải Bổ Sung Thức Ăn Và Thuốc Như Thế Nào? 9 Loại Thực Phẩm Bổ Máu Tốt Cho Phụ Nữ
Tuy nhiên, trong một số trường hợp bọn họ vẫn rất có thể tìm được cách thức nhằm tìm được nghiệm khoảng hoặc điểm cực tiểu. (Nếu bọn họ vẫn nhớ lịch trình toán thù ôn thi đại học thì điểm rất tiểu không có thể sẽ đề nghị là vấn đề khiến cho hàm số đạt giá trị nhỏ dại nhất).
Một bí quyết dễ dàng và đơn giản nhằm giải bài bác toán ((2)) là xen kẹt giải (mathbfY) và ( mathbfM) khi đổi mới còn lại được cố định. Đây là 1 thuật tân oán lặp, cũng là nghệ thuật thông dụng lúc giải bài toán tối ưu. Chúng ta đã lần lượt giải quyết nhì bài xích toán sau đây:
Cố định (mathbfM ), search (mathbfY)Giả sử đang tìm được các centers, hãy tìm những label vector để hàm mất non đạt cực hiếm bé dại duy nhất. Vấn đề này tương tự với việc tìm và đào bới cluster cho mỗi điểm tài liệu.
Lúc những centers là cố định, bài tân oán tìm kiếm label vector mang lại toàn thể dữ liệu hoàn toàn có thể được phân tách nhỏ thành bài bác toán thù tra cứu label vector đến từng điểm dữ liệu (mathbfx_i) nlỗi sau:
Vì chỉ có một trong những phần tử của label vector (mathbfy_i) bởi (1) bắt buộc bài xích toán thù ((3)) hoàn toàn có thể liên tiếp được viết bên dưới dạng đơn giản hơn:
Vì (|mathbfx_i - mathbfm_j|_2^2) chính là bình phương khoảng cách tính trường đoản cú điểm (mathbfx_i ) cho tới center (mathbfm_j ), ta hoàn toàn có thể Tóm lại rằng từng điểm (mathbfx_i ) ở trong vào cluster tất cả center gần nó nhất! Từ đó ta hoàn toàn có thể dễ dãi suy ra label vector của từng điểm dữ liệu.
Cố định (mathbfY ), tra cứu (mathbfM)Giả sử đã tìm kiếm được cluster mang đến từng điểm, hãy tìm center mới cho từng cluster nhằm hàm mất mát đạt quý hiếm nhỏ dại nhất.
Một lúc bọn họ sẽ khẳng định được label vector cho từng điểm tài liệu, bài toán search center cho mỗi cluster được rút gọn gàng thành:
Đặt (l(mathbfm_j)) là hàm bên trong dấu (argmin), ta tất cả đạo hàm:
Giải phương thơm trình đạo hàm bởi 0 ta có:
Nếu xem xét một ít, họ vẫn thấy rằng chủng loại số chính là phép đếm con số những điểm dữ liệu trong cluster (j) (quý khách bao gồm phân biệt không?). Còn tử số đó là tổng các điểm dữ liệu vào cluster (j). (Nếu bạn đọc vẫn ghi nhớ điều kiện buộc ràng của các (y_ij ) thì đã hoàn toàn có thể gấp rút nhìn ra điều này).
Hay nói một bí quyết đơn giản dễ dàng rộng nhiều: (mathbfm_j) là trung bình cùng của những điểm trong cluster (j).
Tên gọi K-means clustering cũng xuất phát từ trên đây.
Tóm tắt thuật toán
Tới đây tôi xin được bắt tắt lại thuật toán thù (quan trọng đặc biệt đặc trưng cùng với các bạn bỏ qua mất phần toán thù học bên trên) như sau:
Đầu vào: Dữ liệu (mathbfX) và số lượng cluster bắt buộc tra cứu (K).
Đầu ra: Các center (mathbfM) với label vector đến từng điểm tài liệu (mathbfY).
Chọn (K) điểm ngẫu nhiên có tác dụng các center thuở đầu. Phân từng điểm dữ liệu vào cluster bao gồm center sát nó tốt nhất. Nếu việc gán tài liệu vào từng cluster ngơi nghỉ bước 2 ko biến hóa đối với vòng lặp trước nó thì ta giới hạn thuật toán thù. Cập nhật center cho từng cluster bằng cách rước mức độ vừa phải cùng của tất các những điểm tài liệu đã có được gán vào cluster đó sau bước 2. Quay lại bước 2.Chúng ta có thể đảm bảo an toàn rằng thuật tân oán đang tạm dừng sau một vài hữu hạn vòng lặp. Thật vậy, vày hàm mất đuối là một vài dương và sau từng bước 2 hoặc 3, cực hiếm của hàm mất non bị giảm sút. Theo kỹ năng và kiến thức về hàng số trong chương trình cấp cho 3: trường hợp một dãy số bớt cùng bị ngăn bên dưới thì nó hội tụ! mà hơn nữa, số lượng bí quyết phân team cho toàn thể tài liệu là hữu hạn nên đến một lúc làm sao kia, hàm mất non sẽ không còn thể biến đổi, cùng bạn cũng có thể dừng thuật toán tại đây.
Chúng ta sẽ sở hữu một vài ba đàm luận về thuật toán này, về hầu như hạn chế và một số phương pháp hạn chế và khắc phục. Nhưng trước tiên, hãy xem nó biểu hiện như thế nào trong một ví dụ ví dụ tiếp sau đây.
3. ví dụ như bên trên Python
Giới thiệu bài xích toán
Để chất vấn mức độ gọi quả của một thuật toán, chúng ta sẽ làm một ví dụ đơn giản và dễ dàng (thường được Điện thoại tư vấn là toy example). Trước không còn, chúng ta lựa chọn center mang đến từng cluster và chế tạo ra tài liệu cho từng cluster bằng cách mang chủng loại theo phân păn năn chuẩn bao gồm mong muốn là center của cluster kia với ma trận hiệp pmùi hương không nên (covariance matrix) là ma trận đơn vị.
Xem thêm: 9 Lưu Ý Khi Mang Thai Tháng Thứ 3 Nên Ăn Gì Để Bé Thông Minh, Mẹ Khỏe Mạnh? ?
Thứ nhất, bọn họ nên khai báo những tlỗi viện buộc phải dùng. Chúng ta buộc phải numpy cùng matplotlib như vào bài bác Linear Regression cho vấn đề tính tân oán ma trận với hiển thị dữ liệu. Chúng ta cũng cần phải thêm thỏng viện scipy.spatial.distance để tính khoảng cách giữa các cặp điểm trong nhì tập hợp một giải pháp kết quả.